
La mayoría de desarrolladores que empiezan con Claude Code cometen el mismo error.
No está en los prompts. Está en que abren el terminal y empiezan a trabajar sin configurar nada. Sin estructura. Sin reglas. Sin memoria.
El resultado: Claude toma decisiones arbitrarias sobre nomenclatura, arquitectura y convenciones porque nadie le ha dicho cómo se trabaja en ese proyecto. Se pasa más tiempo corrigiendo que avanzando.
El punto de inflexión llega cuando se entiende qué es el directorio .claude/ y por qué ignorarlo es el error más común entre los desarrolladores que empiezan con Claude Code.
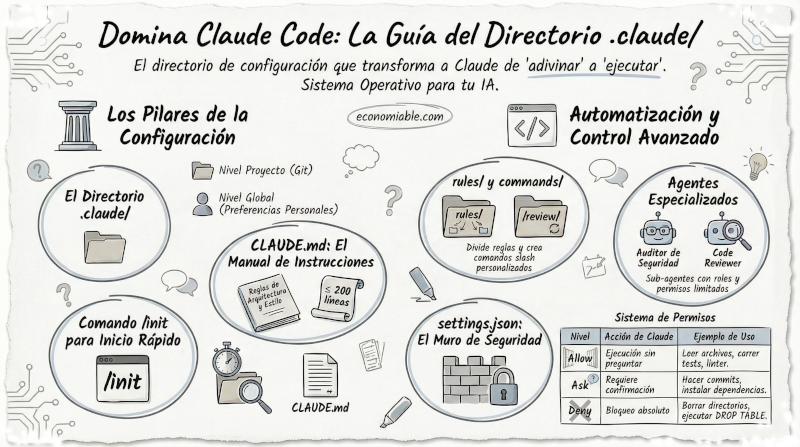
¿Qué es el directorio .claude/?
Es el sistema operativo de Claude Code para tu proyecto.
Cuando Claude Code arranca, lee este directorio antes de que escribas el primer mensaje. Todo lo que hay dentro le dice cómo comportarse: qué puede hacer solo, qué debe preguntarte, qué convenciones seguir, qué comandos usar, qué está prohibido.
Sin él, Claude adivina. Con él, Claude ejecuta.
Existe en dos ubicaciones con propósitos distintos.
El directorio .claude/ dentro de tu proyecto se versiona en Git, lo comparte el equipo y contiene las reglas específicas del proyecto. Cuando un compañero clona el repositorio, Claude ya sabe cómo funciona ese proyecto.
El directorio ~/.claude/ en tu directorio home es personal, nunca se commitea y aplica a todos tus proyectos. Son tus preferencias como desarrollador: tu estilo de respuesta, tus atajos, tus convenciones globales.
Ambos se cargan simultáneamente. Las reglas del proyecto tienen prioridad cuando hay conflicto.
La anatomía del directorio .claude/
CLAUDE.md — El manual de instrucciones
Es el archivo más importante. Claude Code lo lee siempre, en cada sesión, antes de cualquier prompt.
Aquí va lo que Claude necesita saber para trabajar en el proyecto sin necesidad de explicárselo cada vez: cómo se arranca, cómo se testea y cómo se despliega; qué patrones arquitectónicos se usan y cómo está organizado el código; los nombres de archivos, el estilo de código, el idioma de los comentarios y el formato de los commits; y qué archivos no se tocan, qué dependencias no se instalan sin permiso y qué nunca va al repositorio.
La regla práctica: mantenerlo por debajo de 200 líneas. Si crece demasiado, pierde efectividad. Lo que no cabe con claridad en 200 líneas tiene su propio sitio.
Un CLAUDE.md bien escrito convierte a Claude Code en un desarrollador que ya conoce el proyecto desde el primer día.
El comando /init — El punto de partida que casi nadie conoce
Crear un CLAUDE.md desde cero puede parecer una barrera, especialmente en proyectos ya en marcha. Para eso existe el comando /init.
Al ejecutarlo, Claude Code analiza la estructura del proyecto, los archivos de configuración, las dependencias y el código existente, y genera automáticamente un CLAUDE.md con un punto de partida razonable. No es perfecto, pero es un 70% del trabajo hecho en segundos.
A partir de ahí, el flujo es sencillo: revisar lo que ha generado, eliminar lo que no aplica, completar lo que falta y ajustar las convenciones específicas del equipo. Es infinitamente más rápido que escribirlo desde cero.
Es el primer paso práctico al abrir Claude Code en cualquier proyecto existente.
CLAUDE.md anidados — Instrucciones por módulo
No tiene que haber un único CLAUDE.md en la raíz del proyecto. Claude Code soporta archivos CLAUDE.md anidados dentro de subcarpetas, y cada uno aplica únicamente cuando se trabaja en ese módulo.
Un proyecto con frontend y backend separados puede tener un CLAUDE.md en la raíz con las reglas generales, otro dentro de /api con las convenciones específicas de los endpoints y otro dentro de /frontend con las reglas de componentes y estilos. Claude carga solo los que son relevantes para los archivos que está tocando en cada momento.
Esto es especialmente útil en monorepos, donde conviven varios proyectos con stacks o convenciones distintas bajo el mismo repositorio. Cada módulo tiene su propio contexto sin contaminar el de los demás.
rules/ — Reglas modulares por ámbito
Cuando CLAUDE.md se queda pequeño, la solución no es hacerlo más largo. Es dividirlo.
La carpeta rules/ contiene archivos de reglas separados por responsabilidad. Por ejemplo: code-style.md para las convenciones de estilo y nomenclatura, testing.md para cómo escribir tests y qué cobertura se espera, api-conventions.md para la estructura de los endpoints, database.md para queries y migraciones, y security.md para todo lo que nunca se expone.
Lo que los hace especialmente útiles es el YAML frontmatter: permite indicar que un archivo de reglas solo se cargue cuando Claude está trabajando en ciertos paths del proyecto. Así, api-conventions.md solo consume contexto cuando Claude está tocando archivos dentro de la carpeta de API. Para proyectos grandes, esto marca una diferencia notable en la coherencia y eficiencia de las respuestas.
commands/ — Flujos de trabajo repetibles como slash commands
Los commands son recetas que se pueden invocar con /nombre-del-comando directamente desde la sesión.
Lo que los diferencia de un simple prompt es que ejecutan comandos de shell reales e inyectan su output en el contexto. Claude no trabaja sobre suposiciones, sino sobre datos reales.
Algunos ejemplos que tienen sentido en cualquier proyecto: /review ejecuta el linter y los tests, captura el output y pide una revisión de código completa con ese contexto real; /fix-issue recibe el número de un issue, hace fetch de su contenido y arranca una sesión de debugging con toda la información; /deploy-check corre la checklist de pre-deploy y genera un resumen de si está todo listo; /db-status ejecuta consultas de diagnóstico en la base de datos e interpreta el resultado.
La lógica es simple: si algo se hace más de tres veces, debería ser un command.
skills/ — Capacidades que Claude activa solo
Los skills son similares a los commands pero con una diferencia clave: Claude los activa de forma automática, sin necesidad de invocarlos. Cuando detecta que la tarea encaja con el patrón de un skill, lo carga y lo aplica.
Mientras un command es un atajo manual, un skill es un reflejo entrenado.
Además, los skills son paquetes completos, no archivos sueltos. Un skill puede incluir las instrucciones del proceso, templates, sub-reglas y comandos auxiliares. Esto los hace adecuados para tareas complejas y recurrentes: añadir autenticación a un módulo, crear un nuevo microservicio siguiendo el patrón del proyecto, migrar una base de datos.
agents/ — Subagentes especializados con personalidad propia
Es el nivel más avanzado. En lugar de un Claude genérico para todo, es posible definir agentes especializados, cada uno con sus propias herramientas, permisos y modelo configurado.
Algunos ejemplos: un Code Reviewer que solo puede leer, nunca modificar; un Security Auditor sin acceso a red ni escritura, dedicado exclusivamente a detectar vulnerabilidades; un Database Agent que consulta pero no puede ejecutar ningún UPDATE, DELETE o DROP; un Deploy Agent activo solo en CI/CD, sin acceso al código fuente.
Cada agente opera en su dominio con sus propias restricciones. Se pueden orquestar en paralelo o en secuencia para tareas complejas.
settings.json — El control de permisos
Define exactamente qué puede hacer Claude sin pedir confirmación, qué debe consultar antes de ejecutar, y qué está bloqueado por completo.
Se estructura en tres niveles. En Allow van los comandos que Claude puede ejecutar en cualquier momento sin preguntar: leer archivos, correr los tests, ejecutar el linter, consultar el estado de Git. En Ask van las acciones que Claude debe mostrar antes de ejecutar y para las que necesita confirmación: instalar dependencias, hacer commits, hacer push. En Deny va lo que está bloqueado absolutamente, independientemente de lo que se le pida: borrar directorios de forma recursiva, ejecutar DROP TABLE, escribir en el archivo .env.
Este sistema es lo que permite dejar a Claude trabajar de forma semi-autónoma sin miedo a que haga algo irreversible. La confianza en la automatización viene de tener los límites bien definidos.